Двоичная система счисления
Каждая система счисления использует позиционные обозначения разрядов чисел (их значений). Каждое следующее позиционное значение состоит из предыдущего позиционного значения, умноженного на 2 (именно на 2, так как это бинарная система, которая состоит из двух чисел). Если битом является , то позиционное значение умножается на 2, а если — позиционное значение остается . В бинарной системе счисления отсчет ведется справа налево, а не слева направо (как в десятичной системе).
Например, в следующей таблице показаны позиционные значения 8-битного двоичного числа :
| Бит | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Позиционное значение | 128 | 64 | 32 | 16 | 8 | 4 | 1 |
| Номер бита | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
Значение бинарного числа равно сумме позиционных значений всех бит:
Двоичное = десятичное .
Примечание: Детально о конвертации чисел из двоичной системы в десятичную и наоборот, а также о сложении двоичных чисел, читайте в материалах урока №44.
Инструкции DIV и IDIV
Операция деления генерирует два элемента: частное и остаток. В случае умножения переполнения не происходит, так как для хранения результата используются регистры двойной длины. Однако в случае деления, переполнение может произойти. Если это произошло, то процессор генерирует прерывание.
Инструкция DIV (от англ. «DIVIDE») используется с данными unsigned, а инструкция IDIV (от англ. «INTEGER DIVIDE») используется с данными signed.
Синтаксис инструкций DIVIDIV:
Делимое находится в аккумуляторе. Обе инструкции могут работать с 8-битными, 16-битными или 32-битными операндами. Данная операция влияет на все 6 флагов состояния.
Рассмотрим следующие 3 сценария:
Сценарий №1: Делителем является значение типа byte. Предполагается, что делимое находится в регистре AX (16 бит). После деления частное переходит в регистр AL, а остаток переходит в регистр AH:
Сценарий №2: Делителем является значение типа word. Предполагается, что делимое имеет длину 32 бита и находится в регистрах DX и AX. Старшие 16 бит находятся в DX, а младшие 16 бит — в AX. После деления 16-битное частное попадает в регистр AX, а 16-битный остаток — в регистр DX:
Сценарий №3: Делителем является значение типа doubleword. Предполагается, что размер делимого составляет 64 бита и оно размещено в регистрах EDX и EAX. Старшие 32 бита находятся в EDX, а младшие 32 бита — в EAX. После деления 32-битное частное попадает в регистр EAX, а 32-битный остаток — в регистр EDX:
В следующем примере мы делим 8 на 2. Делимое 8 сохраняется в 16-битном регистре AX, а делитель 2 — в 8-битном регистре BL:
section .text
global _start ; должно быть объявлено для использования gcc
_start: ; сообщаем линкеру входную точку
mov ax,’8′
sub ax, ‘0’
mov bl, ‘2’
sub bl, ‘0’
div bl
add ax, ‘0’
mov , ax
mov ecx,msg
mov edx, len
mov ebx,1 ; файловый дескриптор (stdout)
mov eax,4 ; номер системного вызова (sys_write)
int 0x80 ; вызов ядра
mov ecx,res
mov edx, 1
mov ebx,1 ; файловый дескриптор (stdout)
mov eax,4 ; номер системного вызова (sys_write)
int 0x80 ; вызов ядра
mov eax,1 ; номер системного вызова (sys_exit)
int 0x80 ; вызов ядра
section .data
msg db «The result is:», 0xA,0xD
len equ $- msg
segment .bss
res resb 1
|
1 |
section.text global_start; должно быть объявлено для использования gcc _start; сообщаем линкеру входную точку movax,’8′ subax,’0′ movbl,’2′ subbl,’0′ divbl addax,’0′ movres,ax movecx,msg movedx,len movebx,1; файловый дескриптор (stdout) moveax,4; номер системного вызова (sys_write) int0x80; вызов ядра movecx,res movedx,1 movebx,1; файловый дескриптор (stdout) moveax,4; номер системного вызова (sys_write) int0x80; вызов ядра moveax,1; номер системного вызова (sys_exit) int0x80; вызов ядра section.data msgdb»The result is:»,0xA,0xD lenequ$-msg segment.bss resresb1 |
Результат выполнения программы:
Оговорочки
Хочу сразу оговориться, что правильно говорить не «ассемблер» (assembler), а «язык ассемблера» (assembly language), потому как ассемблер – это транслятор кода на языке ассемблера (т.е. по сути, программа MASM, TASM, fasm, NASM, UASM, GAS и пр., которая компилирует исходный текст на языке ассемблера в объектный или исполняемый файл). Тем не менее, из соображения краткости многие, говоря «ассемблер» (асм, asm), подразумевают именно «язык ассемблера».
Синтаксис директив, стандартных макросов и пр. структурных элементов различных диалектов (к примеру, MASM, fasm, NASM, GAS), могут отличаться довольно существенно. Мнемоники (имена) инструкций (команд) и регистров, а также синтаксис их написания для одного и того же процессора примерно одинаковы почти во всех диалектах (заметным исключением среди популярных ассемблеров является разве что GAS (GNU Assembler) в режиме синтаксиса AT&T для x86, где к именам инструкций могут добавляться суффиксы, обозначающие размер обрабатываемых ими данных, что бывает довольно удобно, но там есть и другие нюансы, сбивающие с толку программиста, привыкшего к классическому ассемблеру, к примеру, иной порядок указания операндов, хотя всё это лечится специальной директивой переключения в режим классического синтаксиса Intel).
Поскольку ассемблер – самый низкоуровневый язык программирования, довольно проблематично написать код, который корректно компилировался бы для разных архитектур процессоров (например, x86 и ARM), для разных режимов одного и того же процессора (16-битный реальный режим, 32-битный защищённый режим, 64-битный long mode; а ещё код может быть написан как с использованием различных технологий вроде SSE, AVX, FMA, BMI и AES-NI, так и без них) и для разных операционных систем (Windows, Linux, MS-DOS). Хоть иногда и можно встретить «универсальный» код (например, отдельные библиотеки), скажем, для 32- и 64-битного кода ОС Windows (или даже для Windows и Linux), но это бывает нечасто. Ведь каждая строка кода на ассемблере (не считая управляющих директив, макросов и тому подобного) – это отдельная инструкция, которая пишется для конкретного процессора и ОС, и сделать кроссплатформенный вариант можно только с помощью макросов и условных директив препроцессора, получая в итоге порой весьма нетривиальные конструкции, сложные для понимания.
Язык. Преимущества и отличия от ЯВУ
- знание синтаксиса транслятора ассемблера, который используется (например, синтаксис MASM, FASM и GAS отличается), назначение директив языка ассемблер (операторов, обрабатываемых транслятором во время трансляции исходного текста программы);
- понимание машинных инструкций, выполняемых процессором во время работы программы;
- умение работать с сервисами, предоставляемыми операционной системой — в данном случае это означает знание функций Win32 API. При работе с языками высокого уровня очень часто к API системы программист прямо не обращается; он может даже не подозревать о его существовании, поскольку библиотека языка скрывает от программиста детали, зависящие от конкретной системы. Например, и в Linux, и в Windows, и в любой другой системе в программе на Си/Си++ можно вывести строку на консоль, используя функцию printf() или поток cout, то есть для программиста, использующего эти средства, нет разницы, под какую систему делается программа, хотя реализация этих функций будет разной в разных системах, потому что API систем очень сильно различается. Но если человек пишет на ассемблере, он уже не имеет готовых функций типа printf(), в которых за него продумано, как «общаться» с системой, и должен делать это сам.
Оптимальной
- объем используемой памяти (программы-загрузчики, встраиваемое программное обеспечение, программы для микроконтроллеров и процессоров с ограниченными ресурсами, вирусы, программные защиты и т.п.);
- быстродействие (программы, написанные на языке ассемблера выполняются гораздо быстрее, чем программы-аналоги, написанные на языках программирования высокого уровня абстракции. В данном случае быстродействие зависит от понимания того, как работает конкретная модель процессора, реальный конвейер на процессоре, размер кэша, тонкостей работы операционной системы. В результате, программа начинает работать быстрее, но теряет переносимость и универсальность).
языков высокого уровня абстракциисредах быстрого проектирования
Прямая (непосредственная) адресация
Прямой операнд имеет константное значение или выражение. Когда инструкция с двумя операндами использует прямую адресацию, то первый операнд может быть регистром или ячейкой памяти, а второй — непосредственной константой. Первый операнд определяет длину данных. Например:
BYTE_VALUE DB 150 ; определение значения типа byte
WORD_VALUE DW 300 ; определение значения типа word
ADD BYTE_VALUE, 65 ; добавлен непосредственный операнд 65
MOV AX, 45H ; непосредственная константа 45H перемещена в AX
|
1 |
BYTE_VALUEDB150; определение значения типа byte WORD_VALUEDW300; определение значения типа word ADDBYTE_VALUE,65; добавлен непосредственный операнд 65 MOVAX,45H; непосредственная константа 45H перемещена в AX |
Первая программа
Следующая программа на языке ассемблера выведет строку на экран:
section .text
global _start ; необходимо для линкера (ld)
_start: ; сообщает линкеру стартовую точку
mov edx,len ; длина строки
mov ecx,msg ; строка
mov ebx,1 ; дескриптор файла (stdout)
mov eax,4 ; номер системного вызова (sys_write)
int 0x80 ; вызов ядра
mov eax,1 ; номер системного вызова (sys_exit)
int 0x80 ; вызов ядра
section .data
msg db ‘Hello, world!’, 0xa ; содержимое строки для вывода
len equ $ — msg ; длина строки
|
1 |
section.text global_start;необходимодлялинкера(ld) _start;сообщаетлинкерустартовуюточку mov edx,len;длинастроки mov ecx,msg;строка mov ebx,1;дескрипторфайла(stdout) mov eax,4;номерсистемноговызова(sys_write) int0x80;вызовядра mov eax,1;номерсистемноговызова(sys_exit) int0x80;вызовядра section.data msg db’Hello, world!’,0xa;содержимоестрокидлявывода len equ$-msg;длинастроки |
Результат выполнения программы:
Инструкция OR
Инструкция OR выполняет побитовую операцию ИЛИ. Побитовый оператор ИЛИ возвращает , если совпадающие биты одного или обоих операндов равны , и возвращает , если оба бита равны нулю. Например:
Операция OR может быть использована для указания одного или нескольких бит. Например, допустим, что регистр AL содержит , и нам необходимо установить четыре младших бита. Мы можем сделать это, используя оператор OR со значением (т.е. с регистром FH):
OR BL, 0FH ; эта строка устанавливает для BL значение 0011 1111
| 1 | ORBL,0FH; эта строка устанавливает для BL значение 0011 1111 |
В качестве другого примера давайте сохраним значения и в регистрах AL и BL соответственно. Таким образом, следующая инструкция:
OR AL, BL
| 1 | ORAL,BL |
Должна сохранить в регистре AL:
section .text
global _start ; должно быть объявлено для использования gcc
_start: ; сообщаем линкеру входную точку
mov al, 5 ; записываем 5 в регистр AL
mov bl, 3 ; записываем 3 в регистр BL
or al, bl ; выполняем операцию OR с регистрами AL и BL, результатом должно быть число 7
add al, byte ‘0’ ; выполняем конвертацию из десятичной системы в ASCII
mov , al
mov eax, 4
mov ebx, 1
mov ecx, result
mov edx, 1
int 0x80
outprog:
mov eax,1 ; номер системного вызова (sys_exit)
int 0x80 ; вызов ядра
section .bss
result resb 1
|
1 |
section.text global_start; должно быть объявлено для использования gcc _start; сообщаем линкеру входную точку moval,5; записываем 5 в регистр AL movbl,3; записываем 3 в регистр BL oral,bl; выполняем операцию OR с регистрами AL и BL, результатом должно быть число 7 addal,byte’0′; выполняем конвертацию из десятичной системы в ASCII movresult,al moveax,4 movebx,1 movecx,result movedx,1 int0x80 outprog moveax,1; номер системного вызова (sys_exit) int0x80; вызов ядра section.bss resultresb1 |
Результат выполнения программы:
Схематичная структура кода на ассемблере.
Схематично структура исходного кода программы .COM выглядит так:
;Стандартный вид программы типа .COM
.model tiny ; for СОМ
.code ; code segment start
org 100h ; offset in memory = 100h (for COM)
start: ; точка входа
… код ; (.code — сегмент уже определён выше)
… данные
… константы
… стек
end start
|
1 |
;Стандартный вид программы типа .COM .modeltiny; for СОМ .code; code segment start org100h; offset in memory = 100h (for COM) start; точка входа …код; (.code — сегмент уже определён выше) …данные …константы …стек endstart |
Но для удобства программиста можно написать и так:
;Не стандартный вид программы типа .COM — кому-то покажется более удобным разбить сегменты на части
.model tiny ; for СОМ
.code ; code segment start
org 100h ; offset in memory = 100h (for COM)
start: ; точка входа
… код ; (.code — сегмент уже определён выше)
.const
… константы
.data
… данные
.code
… код
.data
… и снова данные
.code
… и снова код
.data
…
.code
…
.data?
… не инициализированные данные
.code
…
end start
|
1 |
;Не стандартный вид программы типа .COM — кому-то покажется более удобным разбить сегменты на части .modeltiny; for СОМ .code; code segment start org100h; offset in memory = 100h (for COM) start; точка входа …код; (.code — сегмент уже определён выше) .const …константы .data …данные .code …код .data …исноваданные .code …исновакод .data … .code … .data? …неинициализированныеданные .code … endstart |
Опустимся по линии абстракции кода ниже. Мы уже знаем и можем назвать один из блоков кода, который имеет имя, параметры и возвращаемое значение. Этот «блок» может вызываться практически неограниченное число раз, будучи написанным один раз Вы уже догадались, что это функция.
В этой статье речь пойдёт о блоках данных. Мы рассмотрим, что такое константа, массив, структура в ассемблере, а также более редко встречающиеся: перечисление, объединение, запись с битовыми полями (запись).
.macro
The commands and allow you to define macros that
generate assembly output. For example, this definition specifies a macro
that puts a sequence of numbers into memory:
.macro sum from=0, to=5
.long \from
.if \to-\from
sum "(\from+1)",\to
.endif
.endm
With that definition, `SUM 0,5′ is equivalent to this assembly input:
.long 0
.long 1
.long 2
.long 3
.long 4
.long 5
-
Begin the definition of a macro called macname. If your macro
definition requires arguments, specify their names after the macro name,
separated by commas or spaces. You can supply a default value for any
macro argument by following the name with `=deflt‘. For
example, these are all valid statements:-
Begin the definition of a macro called , which takes no
arguments. -
Either statement begins the definition of a macro called ,
which takes two arguments; within the macro definition, write
`\p’ or `\p1′ to evaluate the arguments. -
Begin the definition of a macro called , with two
arguments. The first argument has a default value, but not the second.
After the definition is complete, you can call the macro either as
`reserve_str a,b‘ (with `\p1′ evaluating to
a and `\p2′ evaluating to b), or as `reserve_str
,b‘ (with `\p1′ evaluating as the default, in this case
`0′, and `\p2′ evaluating to b).
When you call a macro, you can specify the argument values either by
position, or by keyword. For example, `sum 9,17′ is equivalent to
`sum to=17, from=9′. -
-
Mark the end of a macro definition.
-
Exit early from the current macro definition.
-
maintains a counter of how many macros it has
executed in this pseudo-variable; you can copy that number to your
output with `\@’, but only within a macro definition.
Преимущество C (Си) конвенции по сравнению с PASCAL.
1. Освобождение стека от параметров возлагается на вызывающую процедуру. Это позволяет отимизировать код.
Например, если вызываются несколькл функций подряд, принимающих одни и теже параметры, можно не заполнять стек заново:
….
push b;Второй параметр
push a; Первый параметр — снизу
call myFunc1
call myFunc2
add sp,4; Стек освобождает вызывающая функция
….
|
1 |
…. pushb;Второй параметр pusha; Первый параметр — снизу callmyFunc1 callmyFunc2 addsp,4; Стек освобождает вызывающая функция …. |
2. Более просто создавать функции с изменяемым числом параметров (printf).
How to define an instruction sharing a name with one of the core directives?
It may happen that a language can be in general easily implemented with
macros, but it needs to include a command with the same name as one of
the directives of assembler. While it is possible to override any
instruction with a macro, macros themself may require an access to
the original directive. To allow the same name call a different instruction
depending on the context, the implemented language may be interpreted
within a namespace that contains overriding macro, while all the macros
requiring access to original directive would have to temporarily switch
to another namespace where it has not have been overridden. This would
require every such macro to pack its contents in a «namespace» block.
But there is another trick, related to how texts of macro parameters
or symbolic variables preserve the context under which the symbols within
them should be interpreted (this includes the base namespace and
the parent label for symbols starting with dot).
Unlike the two mentioned occurences, the text of a macro normally does
not carry such extra information, but if a macro is constructed in such way
that it contains text that was once carried within a parameter to another
macro or within a symbolic variable, then this text retains the information
about context even when it becomes a part of a newly defined macro.
For example:
macro definitions end?
namespace embedded
struc LABEL? size
match , size
.:
else
label . : size
end match
end struc
macro E#ND? name
end namespace
match any, name
ENTRYPOINT := name
end match
macro ?! line&
end macro
end macro
end macro
definitions end
start LABEL
END start
The parameter given to «definitions» macro may appear to do nothing, as it
replaces every instance of «end» with exactly the same word — but the text
that comes from the parameter is equipped with additional information about
context, and this attribute is then preserved when the text becomes a part
of a new macro. Thanks to that, macro «LABEL» can be used in a namespace
where «end» instruction has taken a different meaning, but the instances
of «end» within its body still refer to the symbol in the outer namespace.
In this example the parameter has been made case-insensitive, and thus
it would replace even the «END» in «macro» statement that is supposed to
define a symbol in «embedded» namespace. For this reason the identifier
has been split with a concatenation operator to prevent it from being
recognized as parameter. This would not be necessary if the parameter
was case-sensitive (as more usual).
The same effect can be achieved through use of symbolic variables instead
of macro parameters, with help of «match» to extract the text of a symbolic
variable:
define link end
match end, link
namespace embedded
struc LABEL? size
match , size
.:
else
label . : size
end match
end struc
macro END? name
end namespace
match any, name
ENTRYPOINT := name
end match
macro ?! line&
end macro
end macro
end match
start LABEL
END start
This would not work without passing the text through symbolic variable,
because parameters defined by control directives like «match» do not
add context information to the text unless it was already there.
CALM instructions allow for another approach to this kind of problems.
If a customized instruction set is defined entirely in form of CALM,
they may not even need an access to original control directives.
However, if CALM instruction needs to assemble a directive that might not
be accessible, the symbolic variable passed to «assemble» should be
defined with appropriate context for the instruction symbol.
.section name
Use the directive to assemble the following code into a section
named name.
This directive is only supported for targets that actually support arbitrarily
named sections; on targets, for example, it is not accepted, even
with a standard section name.
For COFF targets, the directive is used in one of the following
ways:
.section name[, "flags"] .section name[, subsegment]
If the optional argument is quoted, it is taken as flags to use for the
section. Each flag is a single character. The following flags are recognized:
- bss section (uninitialized data)
- section is not loaded
- writable section
- data section
- read-only section
- executable section
If no flags are specified, the default flags depend upon the section name. If
the section name is not recognized, the default will be for the section to be
loaded and writable.
If the optional argument to the directive is not quoted, it is
taken as a subsegment number (see section ).
For ELF targets, the directive is used like this:
.section name[, "flags"[, @type]]
The optional flags argument is a quoted string which may contain any
combintion of the following characters:
- section is allocatable
- section is writable
- section is executable
The optional type argument may contain one of the following constants:
- section contains data
- section does not contain data (i.e., section only occupies space)
If no flags are specified, the default flags depend upon the section name. If
the section name is not recognized, the default will be for the section to have
none of the above flags: it will not be allocated in memory, nor writable, nor
executable. The section will contain data.
For ELF targets, the assembler supports another type of
directive for compatibility with the Solaris assembler:
.section "name"[, flags...]
Note that the section name is quoted. There may be a sequence of comma
separated flags:
- section is allocatable
- section is writable
- section is executable
Константа в ассемблере.
Мы уже знаем, что значение (конкретное число) можно присвоить переменной, предварительно определив размер этой переменной в байт, слово, двойное слово и т.д.:
- DB — Define Bite.
- DW — Define Word.
- DD — Define Double Word.
- DQ — Define Quatro Bites.
- DT — Define Tetro Bites.
Константа — символ, синоним конкретного числа (выражения, строки), которое, в отличие от переменной нельзя изменить.
Для задания констант применяются обозначения:
- .const — все данные будут восприниматься как константы, до момента изменения сегмента (.data, .code и т.п.).
- = (знак равно).
- equ (может использоваться для создания идентификатора, константного выражения, строки).
Программирование на ассемблер
Написание программы на ассемблере — крайне трудный и затратный процесс
Чтобы создать эффективный алгоритм, необходимо глубокое понимание работы ЭВМ, знание деталей команд, а также повышенное внимание и аккуратность. Эффективность — это критический параметр для программирования на ассемблер
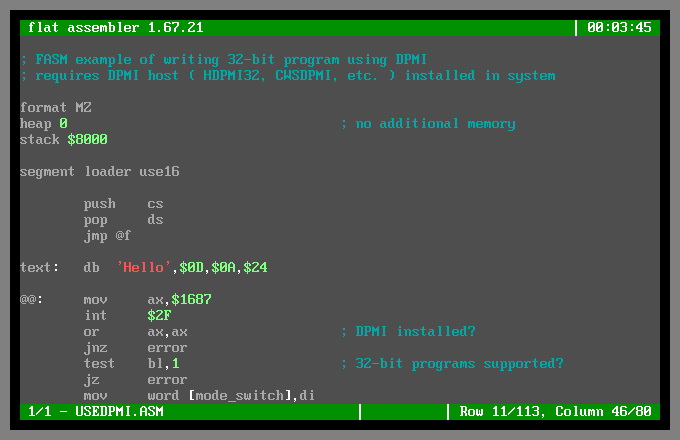
Главное преимущество языка ассемблер в том, что он позволяет создавать краткие и быстрые программы. Поэтому используется, как правило, для решения узкоспециализированных задач. Необходим код, работающий эффективно с аппаратными компонентами, или нужна программа, требовательная к памяти или времени выполнения.
Директивы данных
Языки высокого уровня (C++, Pascal) являются типизированными. То есть, в них используются данные, имеющие определенный тип, имеются функции их обработки и т. д. В языке программирования ассемблер подобного нет. Существует всего 5 директив для определения данных:
- DB — Byte: выделить 1 байт под переменную.
- DW — Word: выделить 2 байта.
- DD — Double word: выделить 4 байта.
- DQ — Quad word: выделить 8 байтов.
- DT — Ten bytes: выделить 10 байтов под переменную.
Буква D означает Define.
Любая директива может быть использована для объявления любых данных и массивов. Однако для строк рекомендуется использовать DB.
Синтаксис:
<name> DQ <operand>
В качестве операнда допустимо использовать числа, символы и знак вопрос — «?», обозначающий переменную без инициализации. Рассмотрим примеры:
real1 DD 12.34
char db ‘c’
ar2 db ‘123456’,0 ; массив из 7 байт
num1 db 11001001b ; двоичное число
num2 dw 7777o ; восьмеричное число
num3 dd -890d ; десятичное число
num4 dd 0beah ; шестнадцатеричное число
var1 dd ? ; переменная без начального значения
ar3 dd 50 dup (0) ; массив из 50 инициализированных эл-тов
ar4 dq 5 dup (0, 1, 1.25) ; массив из 15 эл-тов, инициализированный повторами 0, 1 и 1.25
Типы прыжков
Есть 2 типа выполнения условий в ассемблере:
Прыжок без условия (или «безусловный прыжок») — выполняется инструкцией JMP. Выполнение данной инструкции часто включает в себя передачу управления в адрес инструкции, которая не следует за выполняемой в настоящее время инструкцией. Результатом передачи управления может быть выполнение нового набора инструкций или повторное выполнение текущих инструкций.
Прыжок с условием (или «условный прыжок») — выполняется с помощью инструкций типа и зависит от самого условия. Условные инструкции, изменяя значение смещения в регистре IP, передают управление, прерывая последовательный поток выполнения кода.
Прежде чем разбираться с этими двумя типами инструкций детально, давайте рассмотрим инструкцию CMP.
Объединения в ассемблере.
Объединение (union) — одна и та же область памяти, используемая как разные типы данных. Естественно, в таком случае размер объединения будет равен размеру наибольшего из значений и не равна сумме длин всех запоминаемых, как в структуре. Тип данных создавался для Си, как способ экрномии памяти компьютера (сейчас — не актуально, но ранее активно использовался в написании кода, в том числе и сетевого характера, поэтому применяется и сейчас для совместимости).
- MY_UNION union
_word dw ?
_byte db ?
MY_UNION ends - _union MY_UNION <1234h>
…
После этого _union._word=1234h, а _union._byte=34h.
- xor ax,ax;ax==0
- mov ah,_union._byte
Конвенция вызова функций CDECL (Си, С++ и др.).
Параметры загоняются в стек слева направо — снизу вверх, стек очищается вызывающая функция:
Функция (процедура) содержит пять параметров:myFunc (a,b,c,d,e)
;Ассемблерный код:
push e; Пятый параметр — сверху
push d;
push c;
push b;Второй параметр
push a; Первый параметр (самый левый) — снизу
call myFunc
add sp,10; Стек освобождает вызывающая функция
…
;Функция содержит пять параметров:
myFunc:
push bp
mov bp,sp; Создаём стековый кадр. В bp — указатель на стековый кадр, регистр bp использовать нельзя!
e equ ; Последний параметр — сверху ()
d equ
c equ
b equ
a equ
…
;команды, которые могут использовать стек:
mov ax,e ; считать пятый параметр — . Можно и так, но это менее понятно: mov ax,
; Его адрес в сегменте стека ВР + 4, потому что при выполнении
; команды CALL при вызове функции, в стек поместили адрес возврата — 2 байта для процедуры
; типа NEAR (или 4 — для FAR), а потом еще и ВР — 2 байта (push bp — в начале нашей функции)
mov bx,с ; считать третий параметр — . Можно и так, но это менее понятно: mov bx,
;… ещё команды
…
pop bp
ret ; Из стека дополнительные байты не извлекаются — стек освободит код вызывающей программы (add sp,10)
|
1 |
;Ассемблерный код: pushe; Пятый параметр — сверху pushd; pushc; pushb;Второй параметр pusha; Первый параметр (самый левый) — снизу callmyFunc addsp,10; Стек освобождает вызывающая функция … myFunc pushbp movbp,sp; Создаём стековый кадр. В bp — указатель на стековый кадр, регистр bp использовать нельзя! eequbp+12; Последний параметр — сверху () dequbp+10 cequbp+8 bequbp+6 aequbp+4 … ;команды, которые могут использовать стек: movax,e; считать пятый параметр — . Можно и так, но это менее понятно: mov ax, ; Его адрес в сегменте стека ВР + 4, потому что при выполнении movbx,с; считать третий параметр — . Можно и так, но это менее понятно: mov bx, ;… ещё команды … popbp ret; Из стека дополнительные байты не извлекаются — стек освободит код вызывающей программы (add sp,10) |
.org new-lc , fill
Advance the location counter of the current section to
new-lc. new-lc is either an absolute expression or an
expression with the same section as the current subsection. That is,
you can’t use to cross sections: if new-lc has the
wrong section, the directive is ignored. To be compatible
with former assemblers, if the section of new-lc is absolute,
issues a warning, then pretends the section of new-lc
is the same as the current subsection.
may only increase the location counter, or leave it
unchanged; you cannot use to move the location counter
backwards.
Because tries to assemble programs in one pass, new-lc
may not be undefined. If you really detest this restriction we eagerly await
a chance to share your improved assembler.
Beware that the origin is relative to the start of the section, not
to the start of the subsection. This is compatible with other
people’s assemblers.
When the location counter (of the current subsection) is advanced, the
intervening bytes are filled with fill which should be an
absolute expression. If the comma and fill are omitted,
fill defaults to zero.
Стек
Это область памяти, выделенная для работы процедур. Особенность стека заключается в том, что последние данные, записанные в него, доступны для чтения первыми. Или иными словами: первые записи стека извлекаются последними. Представить этот процесс себе можно в качестве башни из шашек. Чтобы достать шашку (нижнюю шашку в основание башни или любую в середине) нужно сначала снять все, которые лежат сверху. И, соответственно, последняя положенная на башню шашка, при разборе башни снимается первой. Такой принцип организации памяти и работы с ней продиктован ее экономией. Стек постоянно очищается и в каждый момент времени одна процедура использует его.
Основные директивы препроцессора
#include — вставляет текст из указанного файла#define — задаёт макроопределение (макрос) или символическую константу#undef — отменяет предыдущее определение#if — осуществляет условную компиляцию при истинности константного выражения#ifdef — осуществляет условную компиляцию при определённости символической константы#ifndef — осуществляет условную компиляцию при неопределённости символической константы#else — ветка условной компиляции при ложности выражения#elif — ветка условной компиляции, образуемая слиянием else и if#endif — конец ветки условной компиляции#line — препроцессор изменяет номер текущей строки и имя компилируемого файла#error — выдача диагностического сообщения#pragma — действие, зависящее от конкретной реализации компилятора.
Инструкция CMP
Инструкция CMP (от англ. «COMPARE») сравнивает два операнда. Фактически, она выполняет операцию вычитания между двумя операндами для проверки того, равны ли эти операнды или нет. Используется вместе с инструкцией условного прыжка.
Синтаксис инструкции CMP:
Инструкция CMP сравнивает два числовых поля. Операнд назначения может находиться либо в регистре, либо в памяти. Исходным операндом () могут быть константы, регистры или память. Например:
CMP DX, 00 ; сравниваем значение регистра DX с нулем
JE L7 ; если true, то переходим к метке L7
.
.
L7: …
|
1 |
CMPDX,00; сравниваем значение регистра DX с нулем JEL7; если true, то переходим к метке L7 . L7… |
Инструкция CMP часто используется для проверки того, достигла ли переменная-счетчик максимального количества раз выполнения цикла или нет. Например:
INC EDX
CMP EDX, 10 ; сравниваем, достиг ли счетчик значения 10 или нет
JLE LP1 ; если его значение меньше или равно 10, то тогда переходим к LP1
|
1 |
INCEDX CMPEDX,10; сравниваем, достиг ли счетчик значения 10 или нет JLELP1; если его значение меньше или равно 10, то тогда переходим к LP1 |
Подробнее об адресах
Адрес может передаваться несколькими способами:
- В виде имени переменной, которая в ассемблере является синонимом адреса.
- Если переменная является массивом, то обращение к элементу массива происходит через имя его переменной и смещения. Для этого существует 2 формы: и <имя>. Следует учитывать, что смещение — это не индекс в массиве, а размер в байтах. Программисту самому необходимо понимать, на сколько нужно сделать смещение в байтах, чтобы получить нужный элемент массива.
- Можно использовать регистры. Для обращения к памяти, в которой хранится регистр, нужно использовать квадратные скобки: , .
- [] — квадратные скобки допускают применение сложных выражений внутри себя для вычисления адреса: .
В ассемблере адрес передается через квадратные скобки. Ввиду того, что переменная является также адресом, она может использоваться как с квадратными скобками, так и без.
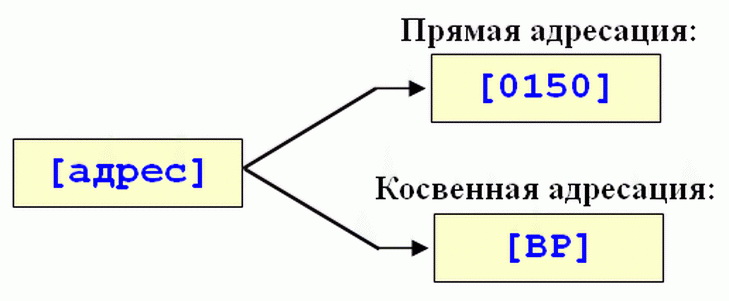
Помимо этого, в ассемблер существуют сокращения: r — для регистров, m — для памяти и i — для операнда. Эти сокращения используются с числами 8, 16 и 32 для указания размера операнда: r8, m16, i32 и т. д.
Похожие записи:
 Как самому изготовить стабилизатор тока для светодиодов: схемы
Как самому изготовить стабилизатор тока для светодиодов: схемы
 Открытая ретро-проводка. пример монтажа
Открытая ретро-проводка. пример монтажа
 Скалер: как сделать полноценный телевизор из жк матрицы монитора компьютера
Скалер: как сделать полноценный телевизор из жк матрицы монитора компьютера
 Кливер 75ас-001 (завода красный луч)
Транзистор кт814: аналоги, характеристики, схемы, чем заменить
Кливер 75ас-001 (завода красный луч)
Транзистор кт814: аналоги, характеристики, схемы, чем заменить
 Подборка схем подключения датчика движения для включения света
Подборка схем подключения датчика движения для включения света